

在大模型的世界里炒股配资王,人们早就习惯了“硬件思维”:显存不够就多加卡,推理太慢就多堆 GPU。长上下文问题因此被视为一场“军备竞赛”——谁能烧更多算力,谁就能撑更长的输入。
但清华大学姚期智团队给出的答案却出乎意料:他们没有再加料,而是直接换了注意力的形态。
在 NeurIPS 2025 上亮相的 TPA(Tensor Product Attention),重新定义了 QKV 的表达方式——不再把每个 token 编码成整块向量,而是拆解为张量因子。就像把一张高清照片折叠成几条信息带,占用空间更小,却能在需要时完整还原。
这意味着,长上下文处理的游戏规则第一次被改写:不再比拼谁堆得更大,而是比拼谁表示得更聪明。

Tensor Product Attention Is All You Need
论文链接:
https://arxiv.org/pdf/2501.06425
项目网站:
https://tensorgi.github.io/TPA/
代码链接:
https://github.com/tensorgi/TPA
为什么“省KV”的路一直走不顺?
大家都知道,KV cache 是长上下文里最先爆掉的那块短板。但为什么这么多年,真正靠谱的“省 KV”方案一直没有跑通?
第一个麻烦,是 KV cache 本身会线性暴涨。每生成一步都要把历史的 K,V 拿出来,全存在显存里很快顶不住;一旦溢出到 off-chip 内存,就直接被 I/O 拘住脚步。
第二个麻烦,是注意力的平方复杂度。标准的 scaled dot-product attention,输入长度
第三个麻烦,是 RoPE 的“黏合剂”不好配。很多压缩或潜表示方法(比如 MLA),在相对位置编码上需要加额外参数或者妥协设计,工程复杂度陡然上升。
所以,前人虽然试过“压缩 KV”,但要么算力没省下来,要么 RoPE 处理不优雅,要么工程落地难度大,最后都成了“治标不治本”的临时方案。
TPA 的思路完全不同:它不是对权重做低秩,而是对激活层做上下文相关的低秩分解。结果是,缓存和计算统统被改写成“因子级”操作,同时还能天然保留 RoPE 的相对位置信息。换句话说,TPA 干净利落地把前人最难啃的三块硬骨头一口气咬碎了。
省 KV 这条路一直走不顺,不是没人试,而是三座拦路虎太硬。TPA 的因子化重写,让这条路第一次真正跑通。
长上下文的维度重写
在标准 Transformer 里,每个 token 的隐状态会被投影成三组向量:Q,K,V。它们就像三张“全尺寸照片”,保存了每个 token 的完整特征。但当上下文长度达到几十万时,这些照片就会越堆越多,KV 缓存体积线性膨胀,推理复杂度也随之平方级上升。换句话说,显存炸裂和计算卡顿就是必然。
TPA 的突破在于:不再存整张照片,而是只存“信息因子条”。具体做法是把 Q,K,V 重写成低秩外积的形式,如公式所示:
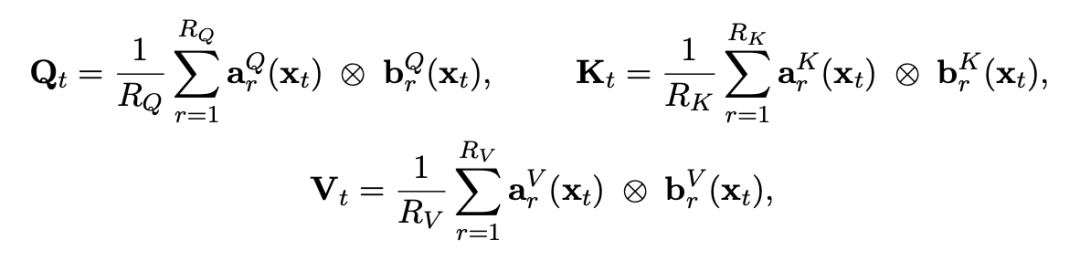
这里的 rank
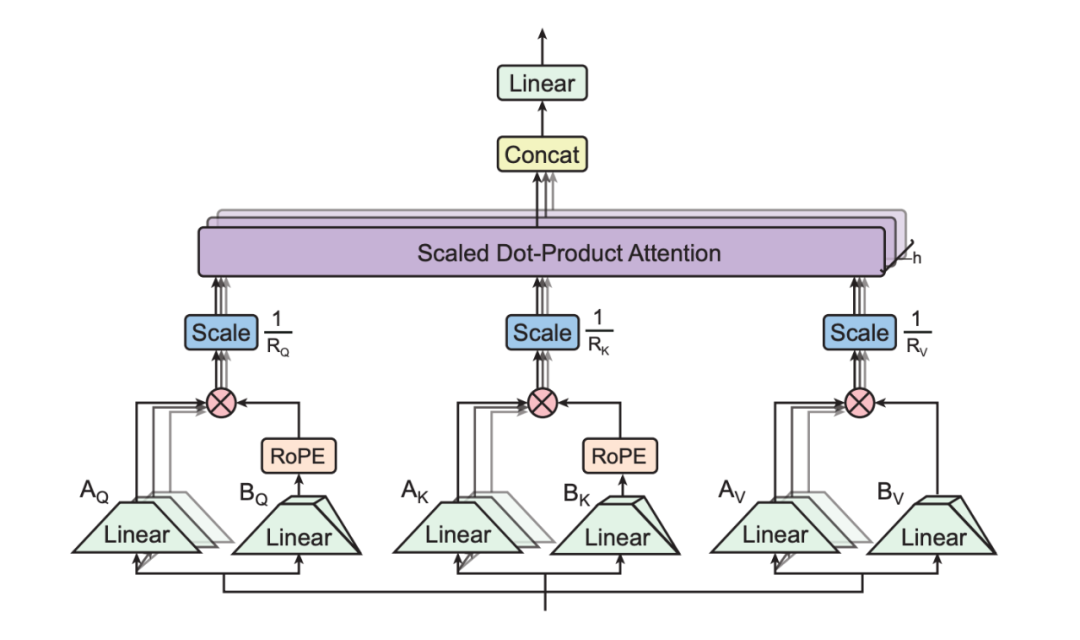
TPA 在注意力层中将 Q/K/V 拆分成因子对 (a,b),RoPE 直接施加在 K 的因子上,与标准 Transformer 架构无缝衔接。
尽管内部表示被改写,注意力的核心计算仍然保持不变。TPA 拼合因子化后的 Q,K,V 后,依然走标准的 scaled dot-product attention:
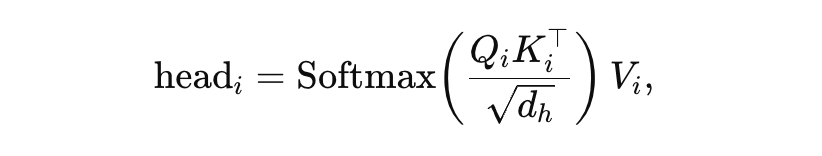
所有 head 拼接后,再线性投影:
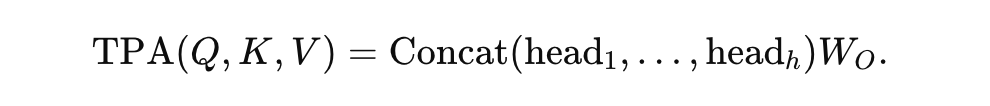
因此,TPA 既能保证架构的兼容性,又能通过因子化降低 KV 存储和计算的压力。
另一个关键点是位置编码。RoPE 在长上下文里不可或缺,通常做法是对整个 Q,K 向量施加旋转。但 TPA 发现,只要把 RoPE 作用在 K 的 B 因子上,就能保留全部的相对位置信息,并且可以提前缓存。论文中的公式写道:
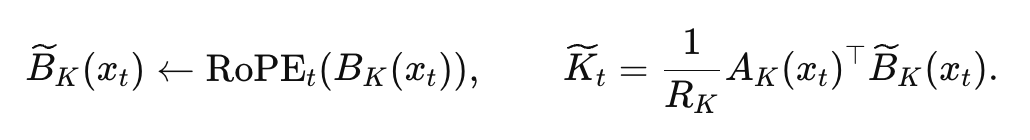
直观来看,过去需要对整张大图旋转,而现在只转动关键的一半,就能达到同样的效果。这让推理时无需再显式旋转,进一步节省了算力。
真正让 TPA 脱颖而出的是推理阶段。传统注意力需要显式构造完整的 Q,K,V 矩阵,然后进行大规模矩阵运算。而在 TPA 中,所有计算都在因子空间完成:

在因子空间直接完成收缩和聚合,避免显式构造 Q/K/V,大幅降低解码延迟。
结果是显存账本被彻底改写:从每个 token 需要
一句话总结:TPA 没有去死抠平方复杂度的常数,而是直接重写了注意力的基本维度:存因子,不存矩阵,KV 缓存骤降;RoPE 融入因子,位置编码无缝衔接;推理在因子空间完成,序列越长越快。
03 越长越省,越大越强
更快收敛,更低困惑度
研究团队首先在 FineWeb-Edu 100B 上训练了 124M、353M、773M 和 1.5B 四档模型,对比 MHA、MQA、GQA、MLA 等常见注意力方案。在相同参数预算下,TPA 在绝大多数阶段都展现出更快的收敛速度和更低的验证困惑度。换句话说,同样跑一遍,TPA 走得更稳、学得更好。
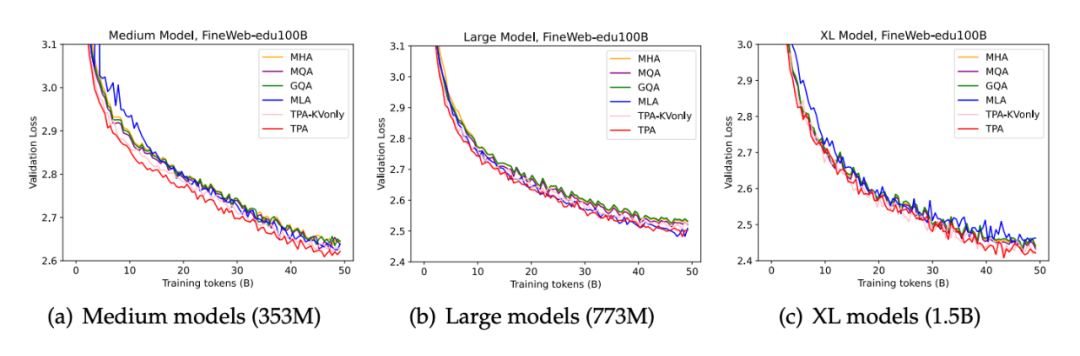
TPA(红线)与 TPA-KVonly(粉线)整体低于其他基线,尤其是 MLA 收敛更慢且最终困惑度更高。
总结:同参同训下,TPA 不仅更快收敛,还能更低困惑度。
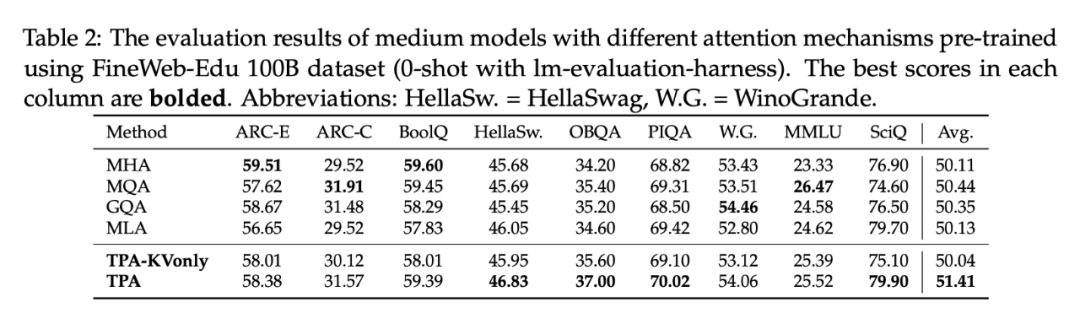
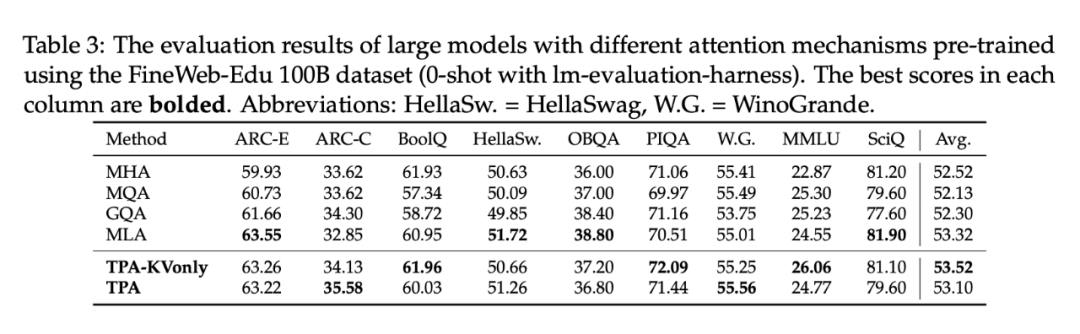
下游评测:0/2-shot全面占优
在 ARC、BoolQ、HellaSwag、OBQA、PIQA、WinoGrande、MMLU、SciQ 等多项下游基准上,TPA 与 TPA-KVonly 在 0-shot 和 2-shot 场景下表现普遍优于其他注意力变体。
例如,353M 档模型的 0-shot 平均分为 51.41%,比 MHA、MQA、MLA 都高;而 773M 档的 TPA-KVonly 更是拿下 53.52% 的均值,稳居榜首。
TPA 与 TPA-KVonly 的平均分整体领先或持平,表现稳定且更具优势。
总结:不只是显存省,TPA 在下游任务上也更强。
解码速度:长序列的真正杀手锏
最后,团队在推理速度上对比了 FlashTPA 与 FlashMHA、MQA、GQA、MLA。在不同 batch size 和序列长度下,FlashTPA 的延迟曲线整体表现优异。在超长序列(例如
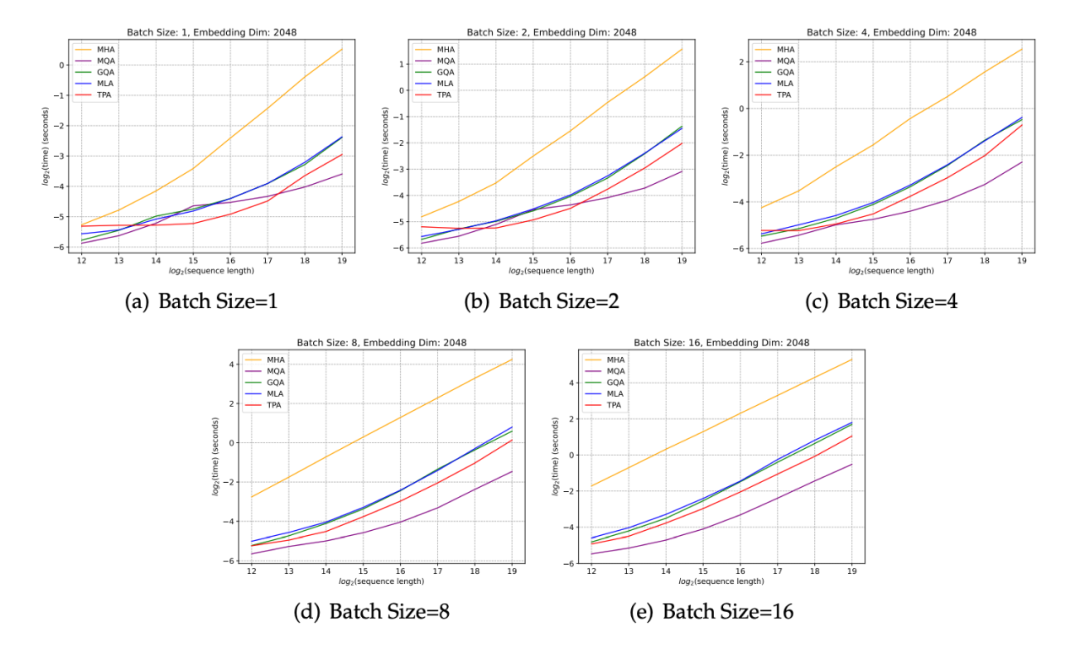
解码时延随长度变化
TPA(红线)的解码延迟并不是最低,MQA 更快一些。但 TPA 在显存占用和超长上下文的稳定性上优势明显。
总结:在超长上下文下,FlashTPA 跑得越久,优势越大。
整体来看,TPA 在预训练收敛、下游评测和存储效率等维度都展现了优势:收敛更快、困惑度更低、性能更强、显存更省。特别是在长上下文场景中,TPA 不仅没有掉点,反而越长越稳。这让它不仅是“节省显存的小技巧”,更是能真正改变长上下文训练与推理范式的关键方法。
04 一行接入,立刻加速
TPA 的爽点在于:它不是实验室里的花架子,而是你今天就能一行接入的外挂。
在多轮对话、RAG 检索、代码助手这些典型场景里,TPA 的因子化缓存只需压缩一次,就能在不同查询间多次复用,直接省下大半算力。复杂度从
更妙的是,TPA 并不是替代,而是叠加。FlashAttention、PagedAttention 这些已有的加速神器,可以与 TPA 无缝组合,收益直接叠加,速度再上一个档位。
总结:TPA 不是纸上谈兵,而是今天就能接入的外挂:压一次、多次用,显存立省,推理加速,体验升级。
05 从算力豪赌到范式转变
长上下文过去的突破逻辑是单一路径:显存更大、GPU 更多,才能硬撑 128k 以上的输入。但这其实从未触及问题的核心——注意力机制本身的表示方式。
TPA 的出现,把这个叙事彻底改写。它不是在 Transformer 框架外“另起炉灶”,也不是单纯工程优化,而是在注意力层内部,第一次用因子化重写 QKV,把存储和计算全部转移到“因子空间”。
这意味着:长上下文的成本不再只由硬件堆叠决定,而是由建模方式来塑造。更长的上下文,不是更昂贵,而是更高效、更精准。
TPA 让长上下文的未来,不再由硬件规模定义,而由表示形式决定。
编辑:王菁
关于我们 ]article_adlist-->数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。 ]article_adlist--> ]article_adlist-->新浪微博:@数据派THU
]article_adlist-->新浪微博:@数据派THU微信视频号:数据派THU
今日头条:数据派THU炒股配资王
]article_adlist--> 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
扬帆配资提示:文章来自网络,不代表本站观点。







